Monte Carlo Go Bot
One of the earliest substantial software projects I built was a Go-playing bot for my Extended Project Qualification in sixth form. I had initially planned to build a chess bot, but once I realised how well simple brute-force algorithms could perform in chess, I decided to take on a more challenging problem. I turned my attention to Go because, at the time, it was one of the few classical board games in which human players still regularly beat machines.
Go sits in an awkward place for computers: the rules are simple, but the search space is huge, and naive brute force breaks down very quickly. I thought it would be interesting to see how well those algorithms could perform in practice, running on typical consumer hardware across different gameplay scenarios.
Implementation
First, I built a playable Go game engine as a WinForms desktop app in C#. This covered board representation, legal move generation, capture logic, scoring, turn handling, and support for different board sizes. As well as this, by separating the core rules and state from the AI, I added support for the user to play against the bot or another human player.
On top of that engine, I extended the gameplay UI. The interface handled board interaction, configurable thinking time, and move history, so positions could be replayed and inspected. This made testing and debugging much easier.
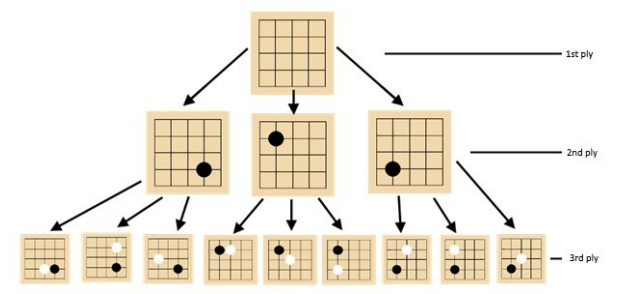
For the bot itself, I implemented Monte Carlo Tree Search, then extended it with UCT to balance exploration against exploitation and RAVE to share information about promising moves across the tree. However, much of the work was not the headline algorithm but the plumbing around it: keeping simulations valid, maintaining tree state, and making sure repeated playouts did not collapse under edge cases. Random playouts were easy to implement but weak at representing actual Go strategy, so the bot could make sensible local decisions while still missing the bigger picture. I also had to deal with awkward edge cases like Ko, where repeated board states can trap a simulation by looping the same moves indefinitely, as well as the broader question of when a simulated game should end.
Reflection
The final program was nowhere near professional-strength, but that was never really the point. What mattered was that it could make coherent decisions, beat a purely random player, and give me a concrete way to study search heuristics, trade-offs in evaluation, and performance limitations.